The new NORDUnet speech2text transcription service will be avalable from February 1, 2026.
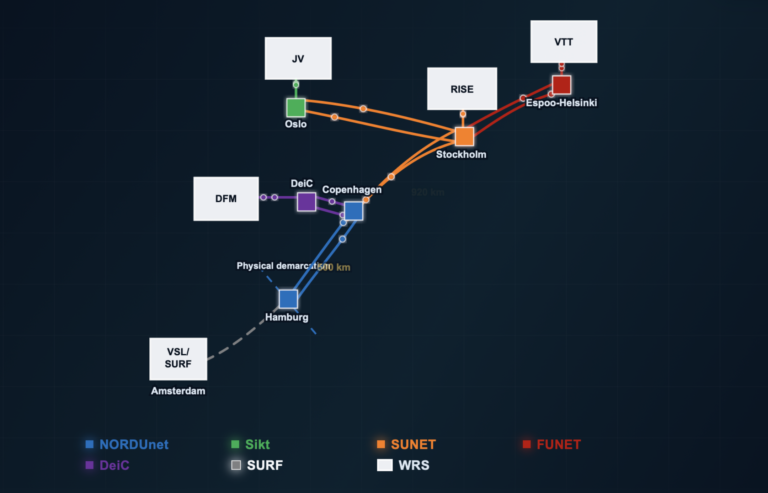
Within the broader Nordic research and education community, the NORDUnet transcription service represents a strategic capability that complements the existing NORDUnet shared services ecosystem, supported by NORDUnet and delivered through the national research and education networks.
As Nordic institutions increasingly explore AI-enabled workflows, the NORDUnet Media Transcription Service stands out as a Nordic on-premise alternative:
- a sovereign, in-region alternative to commercial cloud speech-recognition services
- a model for compliant, privacy-preserving AI operations aligned with Nordic data-protection priorities
- a building block for cross-Nordic interoperability, where similar AI-assisted services may evolve across Denmark, Finland, Iceland, Norway and Sweden.
For NORDUnet, this strengthens the collective Nordic value proposition: secure digital research services, developed regionally but sharable, scalable, and potentially harmonised across borders.
The service was developed as a join effort by Sunet, CSC and NORDUnet.
Service description:
Privacy by design
Login and AAI is using the orgnisation Single Sign On (SSO) solution
Each user has a personal encryption key to ensure privacy of content
Primary Use Cases
NORDUnet Media Transcription Service is designed to support a broad range of sector-specific scenarios, including:
- research interview material
- lectures and academic presentations
- internal training and compliance content
- subtitles and accessibility support for educational media
Access Channels
The stand-alone service is available through two main access paths:
Web interface
Supports file upload and automated transcription, including an admin interface for user management and usage reporting.
Public API
Allows connected organizations to build custom integrations or automate internal workflows.
System Architecture and Workflow
NORDUnet Media Transcription Service is built as an automated processing pipeline:
- Pre-processing of audio/video (noise reduction, normalisation, segmentation)
- AI-based transcription using the Open AI Whisper model, enhanced with national language models.
- Optional speaker diarisation
- Manual post-editing directly in the web interface
- Export in multiple formats
The service supports multiple languages and will expands language coverage progressively.
Core features available:
- selectable transcription modes (faster vs. higher accuracy)
- automatic speaker change detection (diarisation)
- verbatim or cleaned-up transcript output
- export options in multiple formats:
- Subtitles: .srt, .vtt
- Full-text: .rtf, .txt, .csv, .tsv, .json
- Additional formats may be added based on demand
How to get access to the service?
The service can be requested through the regular National NREN (CSC/Funet, DeIC, RHnet and Sikt) channels.
* Sunet has their own version of the service named Scribe